Pandas is a Python library designed to work with dataframes.
Essentially, it adds a ton of usability features to NumPy.
It has become a standard library in data science.
Why Pandas?
Since we already have NumPy as a powerful analytical tool to work with data, why do we need Pandas?
Recall one of the problems we faced when using NumPy — if we want to work with labeled data, say a matrix with named columns and rows, we have to create separate arrays and manage the relationship between the three arrays in our heads.
It would be nice if we could have an object which contained all three together.
This is one the things Panda offers.
Structured Arrays
In fairness, NumPy does offer a partial solution to this problem — structured arrays — which we have not covered.
Structured arrays allow you to create arrays with labeled columns, and these columns may have different data types.
Users looking to manipulate tabular data, such as stored in csv files, may find other pydata projects more suitable, such as xarray, pandas, or DataArray. These provide a high-level interface for tabular data analysis and are better optimized for that use. For instance, the C-struct-like memory layout of structured arrays in numpy can lead to poor cache behavior in comparison. NumPy documentation
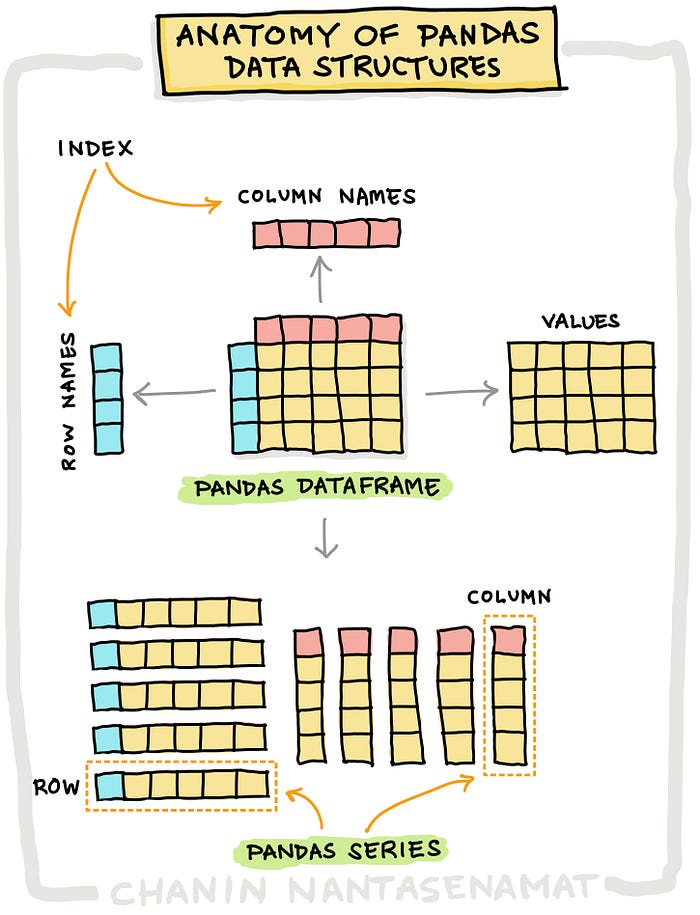
Pandas Data Structures
In a way, Pandas takes the concept of the structured array and runs with it (although the two were developed independently).
In doing so, it makes a strong design decision to only work with \(1\) and \(2\) dimensional arrays:
A \(1\)-dimensional labeled array capable of holding any data type is called a Series.
A \(2\)-dimensional labeled array with columns of potentially different types is called a DataFrame.
As a side note, Pandas used to have a \(3\)-dimensional structure called a panel, but it has been removed from the library for lack of use.
Ironically, the name “pandas” was partly derived the word “panel”, as in “\(pan(el)-da(ta)-s\)”.
To handle higher dimensional data, the Pandas team suggests using XArray, which also builds on NumPy arrays.
This is important — this decision reflects the fact that data science, to a large extent, is practiced in two-dimensional dataspace.
Data Structure Design
Let’s look at how DataFrame and Series objects are designed and built.
It is essential to develop a mental model of what you are working with so operations and functions associated with them make sense.
Remember — data structure design is king.
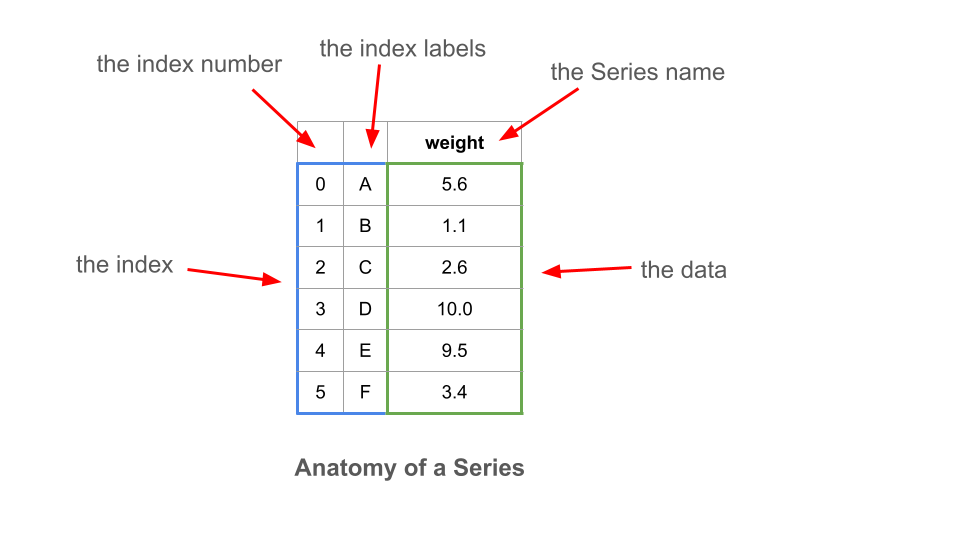
The Series
A Series is at heart a one-dimensional array with labels along its axis.
Labels are essentially names that, ideally, uniquely identify each row (observation).
Its data must be of a single type, like NumPy arrays (which they are internally).
The Index
The axis labels of a Series are referred to as the index of the Series.
Think of the index as a separate data structure that is attached to the array.
The Series array holds the data.
The Series index holds the names of the observations or things that the data are about.
Some consider the index to be metadata — data about data.
Note that if an index does not have labels provided, it falls back on the numeric sequence, like a list.
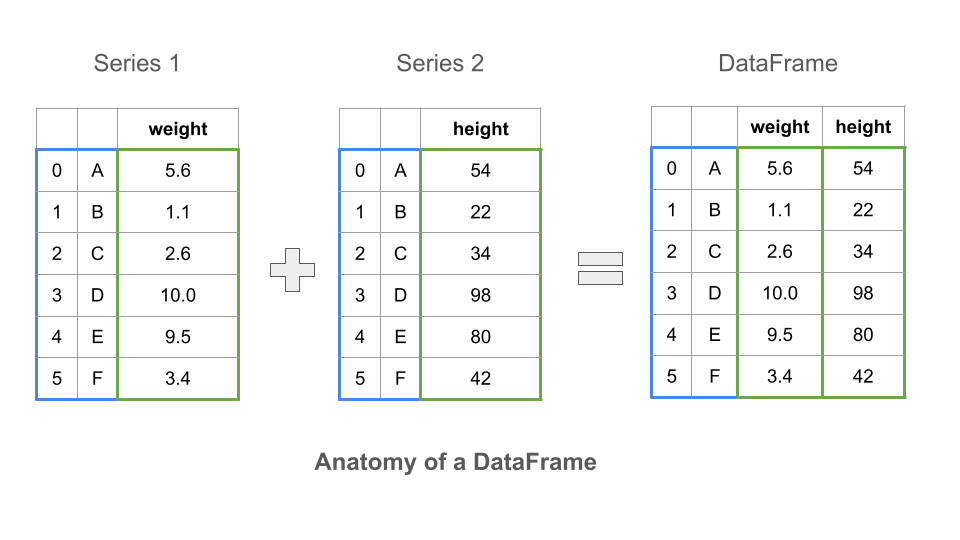
The Data Frame
You can think of a DataFrame as a bundle of Series objects that share an index.
Column labels (also called the column index) can be thought of as Series names.
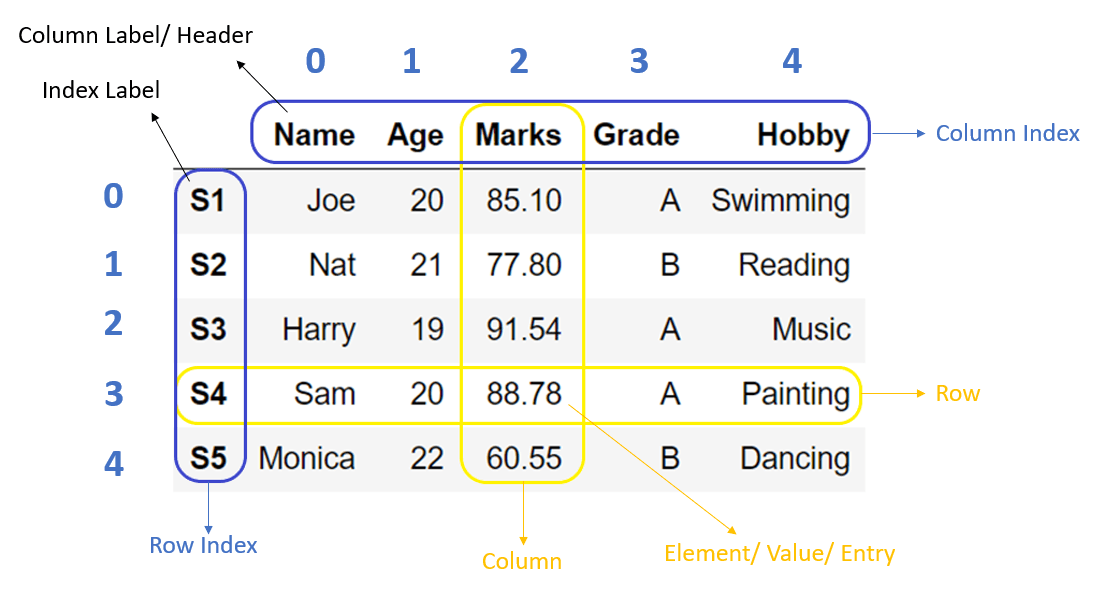
Here’s a more detailed illustration from PYnative 2023:
One way to do this is to assign the .index.name property after construction.
df2.index.name ='obs_id'df2
f1
f2
f3
obs_id
0
a
1
True
1
b
2
False
2
c
4
True
Note how Jupyter represents the index name separately from the column names.
Why have an index?
Indexes provide a way to access elements of the array by name.
They also allow series and data frame objects that share index labels to be combined, through joins and other data operations.
They allow for all kinds of magic to take place when combining and accessing data.
But they are expensive and sometimes hard to work with.
They are especially difficult if you are coming from R and expecting dataframes to behave a certain way.
In any case, an understanding of them is crucial for the effective use of Pandas.
To repeat the point made earlier, a DataFrame is a collection of Series objects with a common index.
To this collection of series, the dataframe also adds a labeled index along the horizontal axis.
The row index is usually just called the index, while the column index is just called the columns.
It is crucial to understand the difference between the index of a dataframe and its data in order to understand how dataframes work.
Many a headache is caused by not understanding this difference :-)
Multidimensional Indexes
Note that both index and column labels can be multidimensional.
These are called Hierarchical Indexes and go the technical name of MultiIndexes.
As an example, consider the following table of sentences in a novel:
books = pd.DataFrame({'book_id': [105, 105, 105, 105, 105, 105],'chap_id': [1, 1, 1, 1, 1, 1],'para_id': [1, 1, 1, 1, 1, 1],'sent_id': [1, 2, 3, 4, 5, 6],'content': ["Sir Walter Elliot, of Kellynch Hall, in Somersetshire, was a man who, for his own amusement, never took up any book but the Baronetage; ", "there he found occupation for an idle hour, and consolation in a distressed one; ", "there his faculties were roused into admiration and respect, by contemplating the limited remnant of the earliest patents; ","there any unwelcome sensations, arising from domestic affairs changed naturally into pity and contempt as he turned over the almost endless creations of the last century; ","and there, if every other leaf were powerless, he could read his own history with an interest which never failed. ","This was the page at which the favourite volume always opened:"]})books
book_id
chap_id
para_id
sent_id
content
0
105
1
1
1
Sir Walter Elliot, of Kellynch Hall, in Somers...
1
105
1
1
2
there he found occupation for an idle hour, an...
2
105
1
1
3
there his faculties were roused into admiratio...
3
105
1
1
4
there any unwelcome sensations, arising from d...
4
105
1
1
5
and there, if every other leaf were powerless,...
5
105
1
1
6
This was the page at which the favourite volum...
Here we use .set_index() to convert some columns to index names.
We create two copies, one “deep” and one “shallow”.
df_deep = df.copy() # deep copy; changes to df will not pass throughdf_shallow = df # shallow copy; changes to df will pass through
If we alter a value in the original …
df.x =1
df
x
y
z
0
1
1
True
1
1
1
False
2
1
0
False
3
1
0
False
… then the shallow copy is also changed …
df_shallow
x
y
z
0
1
1
True
1
1
1
False
2
1
0
False
3
1
0
False
… while the deep copy is not.
df_deep
x
y
z
0
0
1
True
1
2
1
False
2
1
0
False
3
5
0
False
Of course, the reverse is true too — changes to the shallow copy affect the original:
df_shallow.y =99
df
x
y
z
0
1
99
True
1
1
99
False
2
1
99
False
3
1
99
False
So, df_shallow mirrors changes to df, since it references its indices and data. df_deep does not reference df, and so changes to df do not impact df_deep.
Column Data Types
You can access the data types of the columns in a couple of ways.